Le Logotron : jouer avec les préfixes et les
suffixes de la langue française
https://github.com/PatriceDargenton/Logotron
Données : Logotron_fr.xls Logotron_fr.mdb .json txt.json
Documentation : Logotron.html .epub .mobi .pdf
Application en ligne : Logotron/App
Code source : Logotron.vbproj.html
Par Patrice Dargenton : patrice.dargenton@free.fr
http://patrice.dargenton.free.fr/CodesSources/index.html
Version 1.08 du 13/05/2021
Le Logotron est un logiciel qui crée des concepts, simplement en accolant un préfixe et un suffixe de la langue française, comme de nombreux mots courants formés de la sorte : télescope (regarder au loin), agoraphobie (peur des grands espaces et lieux publics), ... L'idée provient de l'espiègle astrophysicien Jean-Pierre Petit, qui a même publié un livre sur le sujet.
A l'origine le logiciel a été programmé pour l'Apple II, et publié dans un magasine informatique dans les années 80 (l'ordinateur individuel, n°18 juin 1980, p. 53), et a été présenté dans l'émission Temps X des frères Bogdanoff sur TF1. Je me suis basé sur la version en JavaScript (programmé par Daniel Oddon) disponible sur le site de J.-P.P., pour en faire une version en VB .Net, puis en C# et Web.
Si l'idée d'inventer des concepts au hasard semble pour le moins farfelu, l'intérêt énorme de ce logiciel est d'apprendre en s'amusant les préfixes et les suffixes de la langue française, ce qui permet de comprendre rapidement l'ensemble des mots formés de la même façon, que l'on trouve dans le dictionnaire français. Le Logotron peut potentiellement former plus de 100 000 néologismes (500 préfixes x 200 suffixes), alors qu'il n'existe que quelques milliers de mots ainsi formés déjà existants (j'en ai identifié plus de 10000, soit 14% des mots du dictionnaire français). J'avais déjà adapté à l'époque le logiciel pour mon Atari, et depuis je connais une bonne partie des suffixes et préfixes de la langue française ! J'avais l'idée de reprendre ce logiciel depuis longtemps, et finalement l'idée d'y ajouter un quiz m'a décidé à le faire, il est généré automatiquement, soit sur des mots farfelus, soit sur les mots du dictionnaire formés de la même façon.
Les
termes préfixe, suffixe, affixe ou segment et racine
La
liste des préfixes et suffixes de la langue française
L'ordre
sémantique des préfixes multiples
Les
racines uniques grecs et latines
Racines
qui ne commencent pas par la même lettre
Racines
distinctes avec le même sens (racines multiples)
Le
dictionnaire des mots du français
Le
dictionnaire de Libre Office
Les
mots du type Logotron trouvés dans le dictionnaire français
Les
mots avec un préfixe et un suffixe
Les
mots avec des préfixes multiples et un suffixe
Les
mots avec un ou plusieurs préfixes et un suffixe
Classement
des préfixes et suffixes par niveau de difficulté
Analyse
de la complexité des mots
Analyse
de la fréquence des mots
Mots
avec préfixe(s) et suffixe
Mots
avec des préfixes multiples et un suffixe
Préfixes
et suffixes potentiels
Les
corrections de la liste d'origine des préfixes et suffixes
Version
originale 1.01 du 02/09/2018
Lexique
Les termes préfixe, suffixe, affixe ou segment et racine
Le préfixe est donc le segment qui commence le mot, tandis que le suffixe est celui qui le termine, par exemple le mot agoraphobie (peur des grands espaces et lieux publics) est composé du préfixe agora- et du suffixe -phobie. Certains mots sont composés de plusieurs préfixes et un suffixe, tel que chromolithographie : chromo- litho- -graphie. J'ai utilisé le terme segment pour désigner aussi bien le préfixe que le suffixe, mais on peut utiliser le terme affixe pour indiquer exactement la même chose. J'ai utilisé le terme racine pour regrouper tous les préfixes ou suffixes qui proviennent de la même racine étymologique, par exemple cardio- et -cardie (comme cardiologie et tachycardie). Certaines définitions correspondent exactement (ou presque) à plusieurs racines distinctes, par exemple les racines "thanato", "nécro" et "morti" (la mort), mais elles sont peu nombreuses, une soixantaine.
L'adjectif "logotronique"
Cet adjectif est un néologisme (néo- -logisme !) formé à partir bien sûr du terme Logotron (logo- : la parole, le verbe, et -tron : instrument, machine, étym. moderne), qui indique qu'il s'agit simplement d'un mot qui peut être généré par le Logotron. C'est soit un mot existant du dictionnaire de la forme préfixe + suffixe (ou préfixes + suffixe), ou bien un mot farfelu généré par le Logotron.
La liste des préfixes et suffixes de la langue française
J'ai commencé à compléter la liste d'origine (celle de J.-P.P.) des préfixes et suffixes, et je suis logiquement tombé sur la page du Wiktionnaire consacrée aux suffixes et préfixes, mais c'est un travail en cours, ces listes ne sont pas complètes, elles ont toutefois l'avantage d'inclure l'étymologie. 99 % des définitions étymologiques du Logotron que j'ai complété provient du Wiktionnaire. J'ai alors trouvé le site du Dr Aly Abbara, vraiment excellent, peut-être bien le plus complet qu'on puisse trouver, ainsi que quelques autres, notamment le dictionnaire des suffixes du Robert. Dans mon classeur Logotron_fr.xls, on peut comparer facilement ces dictionnaires (sauf le Robert) par rapport à la liste du Logotron.
Etablir une liste systématique des préfixes et suffixes est une tache colossale, car pour le Logotron il faut dans la mesure du possible trouver un sens unique et précis pour chaque terme ! La première idée qui m'est venue est d'analyser les mots du dictionnaire ainsi formés avec un préfixe et un suffixe, et d'établir des statistiques sur les préfixes et suffixes les plus fréquents de la langue française.
Comme certains mots contiennent plusieurs préfixes et un suffixe, j'ai adapté le Logotron pour générer aussi de telles combinaisons de mots. Voici un exemple :
chromolithographie : ÉCRITURE DE LA COULEUR DE LA PIERRE : chromo - litho - graphie (technique d'impression en couleur sur la pierre)
Ensuite, j'ai récupéré la liste des préfixes potentiels et suffixes potentiels (celle du Dr Aly Abbara) que je pourrais éventuellement ajouter et voir ainsi quels sont les mots supplémentaires du dictionnaire que je pourrais ainsi identifier. Certains préfixes et suffixes permettront d'identifier plusieurs nouveaux mots, j'ai donc trier les préfixes potentiels et suffixes potentiels par fréquence d'utilisation décroissante (et aussi en distinguant les préfixes et suffixes composables, c'est-à-dire ceux pour lesquels le mot du dictionnaire contient à la fois un préfixe et un suffixe) : une stratégie intéressante consiste donc à ajouter en premier ces préfixes et suffixes, ce qui permet d' "attaquer" le problème de façon assez efficace pour commencer. L'idée est d'ajouter d'abord une liste qui permettra d'identifier un maximum de mots du dictionnaire, et ensuite il suffira d'ajouter les quelques préfixes et suffixes restants en fonction de leur intérêt pour le Logotron.
Cependant, former des mots nouveaux simplement en accolant un préfixe et un suffixe ne fonctionne que pour certaines variantes orthographiques. Par exemple, le préfixe hydro- désigne l'eau, et hydrophobe indique ce qui n'aime pas l'eau. Mais on a aussi hydrate qui désigne certains composés chimiques, il faudrait donc ajouter aussi le préfixe hydr-. Mais si on veut conserver un système simple de génération de mot, alors il faut exclure ces variantes orthographiques. Il nous faut donc deux listes de préfixes et suffixes : une pour le Logotron, et une autre complète pour l'analyse du dictionnaire. J'ai donc créé un classeur Excel, avec un filtre qui vaut, 0, 1 ou 2 : 0 si le préfixe ou suffixe n'est pas retenu (par exemple, l'orthographe est obsolète ou erronée, mais on liste quand même tous les candidats, pour éviter de les rechercher à chaque fois), 1 si le préfixe ou suffixe est correct pour l'analyse du dictionnaire, mais n'est pas retenu pour créer des mots nouveaux avec le Logotron, et 2 pour un préfixe ou suffixe valable pour le Logotron. On peut facilement extraire les informations du classeur Excel pour produire un fichier csv directement lisible pour le Logotron.
Voici quelques préfixes et suffixes non retenus pour le Logotron, mais valables quand même :
éco- : la maison -> l'écologie / l'économie (on utilisera plutôt écono- et écolo- pour le Logotron, si on inclue les origines étymologiques modernes)
entér- : l'intestin
gluc- : le sucre
glyc- : le sucre
hiér- : sacré
hydr- : l'eau
-isme : doctrine / état / profession
-iste : adepte
-ite : inflammation
quart- : quatre
sacchar- : le sucre
styl- : la colonne
-urgie : travail
Voilà pour l'essentiel en ce qui concerne le principe du logiciel. Voyons maintenant les principales difficultés rencontrées pour sélectionner un sens unique pour chaque préfixe et chaque suffixe de la langue française.
Les difficultés
Les adjectifs et les noms
Pour le sens des préfixes et suffixes, on indique soit un nom, soit un adjectif (et parfois on évoque aussi un terme plus abstrait, une direction par exemple).
Exemples :
hydro- : l'eau : Nom
bary- : lourd(e) : Adjectif
bio- : la vie : Nom
cata- : vers le bas : Direction
-céphale : tête : Nom
Pour les préfixes, si c'est un nom, on conserve l'article (par exemple l' devant l'eau), mais pas pour les adjectifs. Pour les suffixes, on ne conserve pas les articles.
Exemples de mots du dictionnaire ainsi formés :
hydrologue : SPÉCIALISTE DE L'EAU : hydro - logue (ici "l'eau" est changé automatiquement en "DE L'EAU", via un bout de code)
barycentre : CENTRE LOURD(E) : bary - centre (pas d'article ici, le sens est "centre de gravité")
catalyse : DÉCOMPOSITION VERS LE BAS : cata - lyse (pas d'article ici, le sens actuel n'est plus vraiment le même que son origine étymologique : qui participe à la dissolution ou la modification ; l'étymologie du préfixe cata- n'est pas facile à définir complètement, car il y a plusieurs sens qui en découle, et ils ne sont pas encore tous renseignés dans le Wiktionnaire)
bicéphale : TÊTE DOUBLE : bi - céphale (préfixe adjectif bi- : pas d'article, ça colle bien)
Les accents
La liste d'origine du Logotron (celle de J.-P.P.) ne comportait pas d'accent (peut-être parce qu'il n'y en avait pas sur le clavier de l'Apple II), mais on peut très bien gérer les accents sans problème, car un préfixe ou un suffixe a presque toujours le même accent (ou pas d'accent) lorsqu'il est utilisé dans le même sens.
Il y a des exceptions, par exemple on trouve le préfixe télé- (ex.: télévision) mais aussi téle- (ex.: télescope). La solution qu'on retient c'est que l'on va utiliser le préfixe télé- avec l'accent pour le Logotron, et utiliser aussi téle- seulement pour l'analyse du dictionnaire :
radiotéléphone : SON RADIO À DISTANCE : radio - télé - phone,
radiotélescope : VISIONNEUSE RADIO À DISTANCE : radio - téle - scope
Le genre masculin ou féminin
Pour les adjectifs, on met "(e)" pour indiquer que l'accord au féminin est possible, par exemple :
barycentre : CENTRE LOURD(E) : bary - centre (masculin)
barysphère : SPHÈRE LOURD(E) : bary - sphère (féminin)
Le pluriel
Pour simplifier le Logotron, on indique toutes les définitions au singulier, dans certains cas, il faudra entendre aussi le pluriel, exemple :
démonologie : ÉTUDE DU DÉMON : démono - logie : étude des démons
(angélologie n'existe qu'avec un sens qui ne s'entend qu'au pluriel, mais le préfixe angélo- n'existe pas encore de toutes façons, et il n'est utilisé qu'avec le suffixe -logie dans le dictionnaire)
Les variantes orthographiques
Certains préfixes ont conservé une double orthographe au cours du temps, par exemple le concept du mouvement -kinèse (ex.: psychokinèse, ou karyokinèse, qui est une variante orthographique de caryocinèse, avec une prononciation différente) existe aussi avec la nouvelle orthographe -cinèse (ex.: chimiocinèse). Pour -cinèse, on indique le sens mouvement, et pour -kinèse, on indique le sens déplacer (en référence à la célèbre et hypothétique psychokinèse ou télékinésie). Du coup, le Logotron pourra utiliser l'un ou l'autre des deux suffixes, avec un sens quasi équivalent, en fait on choisi le sens selon l'usage.
Mais lorsqu'une variante orthographique n'apporte aucune subtilité de sens, on ne conserve que l'orthographe courante pour le Logotron.
Les élisions
Parfois certains termes subissent l'élision d'une lettre, par exemple ici du fait de la répétition de la voyelle o avec paléo- et -onto- :
paléontologie : ÉTUDE DE L'ANCIEN : paléo - logie : 10 < 13 : manque nto (on a trouvé paléo-, mais en empruntant le o de onto-, ce qui n'est pas exact : onto- ne peut pas être trouvé, car palé- n'existe pas, et on commence la recherche par le début et la fin du mot, avec les segments les plus long en premier).
Du coup, avec le simple système consistant à juxtaposer les préfixes et suffixes, on ne peut pas trouver ce mot sans programmer la règle de l'élision du o devant un autre o. Dans le bilan produit après l'analyse du dictionnaire, on liste tous ces mots incomplètement identifiés.
Certains suffixes commencent par une voyelle, notamment -urie (urine) et -urgie (travail). Comme la plupart des préfixes se terminent par un o, le o et le u collés ne vont pas ensemble dans ce cas là, il faudrait faire une élision de la dernière lettre du préfixe, par exemple, au lieu de dire métallourgie, on dira métallurgie (cette fois le préfixe métall- existe). Du coup, on ne va conserver ces deux préfixes (métall- et métallo-) que pour l'analyse du dictionnaire, et un seul pour le Logotron (métallo-), pour la même raison de simplicité.
Depuis la version 1.04 du 05/05/2019, la règle de l'élision du o devant un autre o a été ajoutée, et cette fois paléontologie est bien trouvé. J'ai essayé aussi l'élision de la lettre a devant la lettre a, ce qui permet de trouver quelques mots, mais cela pose plus de problème que ça n'en résous. Pour ce cas de figure, il est plus simple d'ajouter explicitement les variantes de préfixes et suffixes pour obtenir ces mots :
décathlon : SPORT DIX : déc(a) - athlon
heptarchie : GOUVERNANCE SEPT : hept(a) - archie
heptarchique : GOUVERNANCE SEPT : hept(a) - archique
heptathlon : SPORT SEPT : hept(a) - athlon
hexacanthe : ÉPINE SIX : hex(a) - acanthe
mutable : QUI PEUT ÊTRE DE LA MODIFICATION : mut(a) - able
mutateur : AGENT DE LA MODIFICATION : mut(a) - ateur
mutation : ACTION DE LA MODIFICATION : mut(a) - ation
parable : QUI PEUT ÊTRE À COTÉ : par(a) - able
paracousie : AUDITION À COTÉ : par(a) - acousie
paranthélie : SOLEIL À COTÉ CONTRE : par(a) - ant - hélie
paranthrope : HOMME À COTÉ : par(a) - anthrope
pentarchie : GOUVERNANCE CINQ : pent(a) - archie
pentarchique : GOUVERNANCE CINQ : pent(a) - archique
pentarque : GOUVERNEUR CINQ : pent(a) - arque
pentathlon : SPORT CINQ : pent(a) - athlon
tétrarchie : GOUVERNANCE QUATRE : tétr(a) - archie
tétrarchique : GOUVERNANCE QUATRE : tétr(a) - archique
tétrarque : GOUVERNEUR QUATRE : tétr(a) - arque
Les déclinaisons
Est-ce qu'il faut préciser toutes les déclinaisons, ou bien seulement certaines ? Par exemple, avec le suffixe -crate (gouverneur, d'après le sens pouvoir), on peut décliner : -cratie (ex.: démocratie), -cratique (ex.: autocratique) et -cratisme (ex.: technocratisme).
En fait, les mots finissants en -ique désignent des adjectifs, ce ne sont pas vraiment des mots nouveaux, alors que ceux finissants en -isme apportent un sens nouveau : la doctrine ou l'abus d'une doctrine liée au mot. Donc on peut convenir que les adjectifs ne vont servir qu'à l'analyse du dictionnaire, mais ne seront pas proposés par le Logotron, contrairement aux déclinaisons en -isme, par contre c'est intéressant de les ajouter dans tous les cas, car le fait d'utiliser les suffixes généraux -isme et -ique oblige que le terme précédant soit un préfixe et non plus un suffixe. Par exemple le suffixe -trope existe, en revanche le préfixe trop- n'existe pas, on a donc intérêt à ajouter dans la liste -trope (ex.: psychotrope), -tropie (ex.: isotropie), -tropique (ex.: entropique) et -tropisme (ex.: phototropisme) pour identifier toutes ces déclinaisons dans le dictionnaire.
Pour les définitions, on peut essayer de distinguer chaque déclinaison, mais c'est plutôt complexe et pas forcément très pertinent (mieux vaut laisser le même terme dans la définition, par exemple mieux vaut mettre toujours gouvernance pour -cratie, -cratique et -cratisme) :
technocrate : GOUVERNEUR DE LA TECHNIQUE : techno - crate
technocratie : GOUVERNANCE DE LA TECHNIQUE : techno - cratie
technocratique : GOUVERNÉ DE LA TECHNIQUE : techno - cratique
technocratisme : GOUVERNALITÉ DE LA TECHNIQUE : techno - cratisme
Autre exemple : -chrone : temps, -chronique : temporel(le) et -chronisme : temporalité
anachronique : TEMPOREL(LE) DE L'AUTRE / À TRAVERS / À NOUVEAU / VERS LE HAUT : ana - chronique (adjectif signifiant d'un autre temps)
anachronisme : TEMPORALITÉ DE L'AUTRE / À TRAVERS / À NOUVEAU / VERS LE HAUT : ana - chronisme (nom signifiant d'un autre temps aussi)
Ici je n'ai pas d'idée pour décliner le sens :
téléphone : SON À DISTANCE : télé - phone
téléphonie : SON À DISTANCE : télé - phonie
téléphonique : SON À DISTANCE : télé - phonique
Et là non plus :
-morphe : forme (ex.: polymorphe)
-morphie : forme (ex.: polymorphie)
-morphique : forme (ex.: polymorphique)
-morphisme : forme (ex.: polymophisme)
morpho- : la forme (ex.: morphologie)
-morphose : forme (ex.: métamorphose)
Les sens multiples
Certains préfixes ou suffixes peuvent avoir plusieurs sens. Ces sens peuvent avoir un lien entre eux, ce sont des variantes sémantiques, ou alors aucun (par exemple s'ils sont d'origine étymologique distincte). Lorsqu'il n'y pas de lien, le préfixe ou le suffixe est ajouté autant de fois qu'il y a de sens distincts indépendants, sinon les sens sont précisés ensemble, avec le signe / comme séparateur, exemples :
ana- : l'autre / à travers / à nouveau / vers le haut
carni- : la chair / la viande
-cole : cultiver / habiter / rendre un culte
-gène : générateur / origine
trans- : le passage à travers / au-delà
Lorsqu'il y a une évolution du sens depuis son sens d'origine (son sens étymologique), on le précise avec le signe -> :
climato- : l'inclinaison (de la terre) -> le climat
éco- : la maison -> l'écologie / l'économie
-èdre : base -> face
carcino- : le cancer
carcino- : le crustacé
chloro-: vert
chloro-: chloré
-esse : qualité (ex.: sagesse)
-esse : féminin (ex.: doctoresse)
homo- : l'homme (ex.: homo sapiens)
homo- : identique (ex.: homogène)
-mane : maniaque (ex.: cleptomane)
-mane : main (ex.: quadrumane)
-mètre : mesureur (ex.: décimètre)
-mètre : matrice (ex.: endomètre)
trans- : la modification (ex.: transformation)
trans- : le passage à travers / au-delà (ex.: transatlantique)
L'ordre sémantique des préfixes multiples
D'une manière générale, l'analyse du sens des préfixes multiples fonctionne plutôt bien, exemple :
électroencéphalogramme : MESSAGE ÉLECTRIQUE DE LA TÊTE : électro - encéphalo - gramme
périsplénite : INFLAMMATION AUTOUR DE LA RATE : péri - splén - ite
Mais parfois, le sens est différent ou inversé :
encéphalomyélopathie : MALADIE DE LA TÊTE DE LA MOELLE : encéphalo - myélo - pathie
En fait c'est la maladie de la moelle épinière et de la tête : (encéphalo-, myélo-) -pathie.
ichtyopathologie : ÉTUDE DU POISSON DE LA MALADIE : ichtyo - patho - logie
C'est l'inverse : en fait c'est l'étude des maladies du poisson.
Ici l'explication vient d'un problème d'associativité :
ichtyo - (patho - logie) : étude de la maladie du poisson (des maladies du poisson)
(ichtyo - patho) - logie : étude du poisson malade (des poissons malades), ce qui en soi n'est pas très différent, mais par contre, du point de vue de la génération automatique de la définition, comme on procède toujours dans le même ordre, on ne peut générer que cette dernière ("étude du poisson de la maladie").
On le voit bien avec par exemple :
hémopéricarde : CŒUR DU SANG AUTOUR : hémo - péri - carde
hémopéricarde : sang autour du cœur : hémo - (péri - carde)
L'hémopéricarde est un épanchement sanguin dans le péricarde, qui est la membrane séreuse qui enveloppe le cœur. Si on ajoutait le suffixe -péricarde, cela résoudrait ce problème, mais seulement celui-là.
Sinon, cela fonctionne assez bien avec plus de deux préfixes :
aérothermodynamique : MOUVEMENT DE L'AIR DE LA CHALEUR : aéro - thermo - dynamique
échocardiogramme : ÉCRITURE DE L'ÉCHO DU CŒUR : écho - cardio - gramme
paléoanthropologie : ÉTUDE DE L'ANCIEN DE L'HOMME : paléo - anthropo - logie
rhéopneumographie : ÉCRITURE DE L'ÉCOULEMENT DU POUMON : rhéo - pneumo - graphie
spectrophotométrie : MESURE DU SPECTRE DE LA LUMIÈRE : spectro - photo - métrie
L'origine étymologique
Au départ, je comptais limiter le Logotron exclusivement aux racines gréco-latines, mais lors de l'analyse des mots du dictionnaire, j'ai trouvé un petit nombre de racines avec une origine géographique différente, et/ou plus moderne. J'ai donc ajouté une colonne au classeur du Logotron, de manière à préciser l'origine des segments. Si l'étymologie du segment commence par "Du latin", l'origine est "Latin". Si l'étymologie du segment commence par "Du grec", l'origine est "Grec". Si l'origine n'est pas précisée, l'origine par défaut est définie (depuis l'application) en "Gréco-latin" (enumOrigine.sDefaut = sGrecoLatin). Si l'origine du segment remonte au 20ème siècle, l'origine est "Moderne". Sinon on indique la provenance culturelle par le pays d'origine. J'ai ajouté enfin une dernière catégorie permettant d'ajouter des néologismes amusants (par exemple fiscalo-, fumisto-, ...), ce qui permet d'éviter de trancher entre un logiciel sérieux et/ou rigolo. La case à cocher "Gréco-latin" sélectionne tous les segments Latin, Grec, ou Gréco-latin (et ignore donc tous les autres : Moderne, ...).
Certains sens étymologiques sont à la fois anciens et modernes, par exemple le préfixe euro- est formé de l'apocope (coupure) de Europe : Du latin Europa, issu du grec ancien Εὐρώπη, Eurốpê. Il permet de former par exemple les mots récents europhile et eurocrate, il est donc défini comme étant d'origine Moderne. Le préfixe euro- ne servira donc que pour l'analyse du dictionnaire, mais pas pour le Logotron, à moins de décocher la case Gréco-latin.
Autres difficultés
Voici un cas particulier intéressant : crino- n'existe pas en tant que préfixe en premier, mais par contre, il est valable en tant que second préfixe : endocrinologie, exocrinopathie.
endocrine a été formé en 1919 à partir de endo- et -crine, et logiquement endocrinologie en découle. Le préfixe crino- ne servira que pour l'analyse du dictionnaire.
Il faut parfois adapter la définition du préfixe, par exemple pour pan-, pant- et panto- j'ai essayé plusieurs définitions : de tout, tout(e), le tout, mais celle qui colle le mieux dans la plupart des cas est "de tout" (celle d'origine de J.-P.P.) :
pantophobie : CRAINTE DE TOUT : panto - phobie : de tout -> meilleure définition
pantophobie : CRAINTE DU TOUT : panto - phobie : le tout (le -> du)
pantophobie : CRAINTE TOUT(E) : panto - phobie : tout(e)
pantographe : QUI ÉCRIT DE TOUT : panto - graphe
pantographie : ÉCRITURE DE TOUT : panto - graphie
pantographique : ÉCRITURE DE TOUT : panto - graphique
pantomètre : MESUREUR DE TOUT : panto - mètre
pantopode : PIED DE TOUT : panto - pode (animal "tout en pattes")
Pareil pour le préfixe théo- : de dieu, le dieu, le divin, la divinité ?
théologie : ÉTUDE DU DIVIN : théo - logie : le divin (le -> du) -> meilleure définition
théologie : ÉTUDE DE DIEU : théo - logie : de dieu (étude de dieu ou des dieux)
théologie : ÉTUDE DU DIEU : théo - logie : le dieu (le -> du)
théologie : ÉTUDE DE LA DIVINITÉ : théo - logie : la divinité (la -> de la)
théo : LE DIVIN : théo-
théocentrisme : CENTRAGE DU DIVIN : théo - centrisme
théocratie : GOUVERNANCE DU DIVIN : théo - cratie
théogamie : MARIAGE DU DIVIN : théo - gamie
théogonie : PROCRÉATION DU DIVIN : théo - gonie
théologie : ÉTUDE DU DIVIN : théo - logie
théomancie : PRÉDICTION DU DIVIN : théo - mancie
théophanie : APPARITION DU DIVIN : théo - phanie
théophilanthrope : L'HOMME DU DIVIN DE L'AMOUR : théo - phil - anthrope
théophore : PORTEUR DU DIVIN : théo - phore
théosophe : SAGE DU DIVIN : théo - sophe
théosophie : SAGESSE DU DIVIN : théo - sophie
théosophique : À PROPOS DU DIVIN DU SAGE : théo - soph - ique
Et pour le suffixe -théisme, divinité semble être une bonne définition :
anthropothéisme : DIVINITÉ DE L'HOMME : anthropo - théisme
monothéisme : DIVINITÉ UNIQUE : mono - théisme
polythéisme : DIVINITÉ MULTIPLE : poly - théisme
théisme : DIVINITÉ : -théisme
Les racines uniques grecs et latines
Du coup, il y a combien de racines uniques en provenance du grec et du latin dans la langue française ? Pour répondre à cette question, il faut tout d'abord regrouper les variantes de chaque préfixe et suffixe. Pour cela, on peut commencer par établir la liste des sens ou définitions uniques répertoriées dans les préfixes et suffixes. Puis on va regrouper les préfixes avec les suffixes pour établir la liste des racines uniques. Pour cela, il faut retirer l'article présent dans la définition des préfixes (le, la et l', qui permettent d'établir une définition correcte d'un mot complet, de façon automatique). On trouve alors que certaines définitions ont des racines distinctes, par exemple la maladie peut être représentée par le préfixe patho-, mais aussi le préfixe noso-, il s'agit pourtant de racines bien distinctes (noso- : du grec ancien νόσος, nósos (« maladie »), et patho- : du grec ancien πάθος, páthos (« passion, souffrance »).). On va alors utiliser un champ facultatif (Unicité) pour départager ces racines distinctes. Pour le suffixe -mane, le simple fait de préciser l'unicité ne suffit pas encore à distinguer par exemple quadrumane (quatre main) de cleptomane (maniaque du vol). Il suffit alors de préciser un peu plus : "mane (mania)" et "mane (manus)". Cette fois on voit bien la différence, et on peut trier la liste des racines uniques dans le bon ordre, en tenant compte de l'unicité lorsque c'est nécessaire (lorsque le champ est renseigné).
Parfois on veut distinguer plusieurs sens correspondant à une même étymologie, en retenant un segment et une racine pour chaque sens distinct. Par exemple le grec ancien mélos signifie « membre de phrase musicale ou membre anatomique », la racine grec a donc formé des mots avec deux sens distincts (ex.: mélodie et pygomèle), on veut donc avoir deux segments et deux racines distinctes permettant de former indépendamment des mots selon chacun de ses sens. Pour y parvenir, on va à nouveau utiliser le champ unicité pour distinguer le sens lorsque l'étymologie est unique, on écrit donc : "mélos : membre" et "mélos : chant" (on conserve mélos en premier pour que la liste des segments et racines conserve le bon ordre).
Lorsqu'un seul des préfixes ou suffixes d'une racine est utilisé pour le Logotron (signe "L" = sélection 2), alors la racine est utilisée pour le Logotron dans son ensemble, sinon elle est réservée à la seule analyse du dictionnaire (signe "D" = sélection 1).
Pour la liste des segments (préfixes ou suffixes) uniques, on fait pareil, cette fois en distinguant les préfixes des suffixes.
Au final on obtient près de 600 racines gréco-latines uniques (dont une cinquantaine ne seront finalement pas retenu pour le Logotron), et plus de 500 préfixes uniques (dont une trentaine non retenus pour le Logotron), et plus de 200 suffixes uniques (dont une vingtaine non retenus pour le Logotron), ce qui fait près de 100 000 combinaisons pour le Logotron (490 préfixes x 197 suffixes gréco-latins = 96 530 combinaisons pour le Logotron, et 502 préfixes x 200 suffixes = 100 400 combinaisons pour le Logotron avec toutes les origines étymologiques).
Racines qui ne commencent pas par la même lettre
Tous les segments d'une même racine commencent par la même lettre, je n'ai trouvé que très peu d'exceptions :
- kérato- <> cérato-, de kéras (« corne ») dont le génitif est kératos.
- -kinèse, kinési-, -kinésie <> -cinèse, de kinêsis (« mouvement »).
- -urgie, -urgique <> ergo-, de érgon (« travail »).
- -tude <> -itude : -tude est une variante de -itude, du latin -tudo.
Cette vérification est effectuée afin d'éviter des erreurs ou des oublis (et de préciser l'unicité lorsque c'est nécessaire) et des avertissements sont générés (lorsque l'on clique sur le bouton Avert.).
Racines distinctes avec le même sens (racines multiples)
Il existe très peu de racines distinctes avec le même sens, il est donc intéressant de suivre aussi cette liste pour trouver des erreurs ou oublis (en sélectionnant, dans l'onglet Concepts du classeur Logotron_fr.xls, les lignes telles que NbRacines > 1) :
|
Niv. |
Concept |
Racines |
NbRacines |
|
N2 |
à coté |
latéro, para |
2 |
|
N2 |
action |
ation, praxie |
2 |
|
N2 |
agé(e) |
enaire, génaire |
2 |
|
N1 |
ancien(ne) |
archéo, paléo |
2 |
|
N3 |
apparence |
eidos, ïde, phéno |
3 |
|
N1 |
arbre |
arbori, dendron |
2 |
|
N1 |
autour |
circon, péri |
2 |
|
N2 |
autre |
allo, alter, hétéro |
3 |
|
N2 |
avec |
co, syn |
2 |
|
N2 |
bois |
sylvi, xylo |
2 |
|
N2 |
bouche |
oro (oris), stomato |
2 |
|
N1 |
cancer |
cancéro, carcino : cancer |
2 |
|
N1 |
chaleur |
calori, thermo |
2 |
|
N2 |
charbon |
anthraco, carbo |
2 |
|
N1 |
ciel |
astro, météoro |
2 |
|
N2 |
cinq |
penta, quinqua |
2 |
|
N1 |
contre |
anti, contra, para (paro) |
3 |
|
N2 |
corps |
physio, somato |
2 |
|
N1 |
couleur |
chromo, colore |
2 |
|
N1 |
cycle |
cyclo, orbito |
2 |
|
N2 |
doigt |
dactylo, digito |
2 |
|
N1 |
double |
ambi, bi, di, diplo |
4 |
|
N2 |
dynamisme |
cinèse, dyne |
2 |
|
N1 |
eau |
aqua, hydro |
2 |
|
N2 |
écriture |
gramma, grapho |
2 |
|
N1 |
en dehors |
exo, extra |
2 |
|
N3 |
épine |
acantho, échino |
2 |
|
N2 |
estomac |
gastro, ventri |
2 |
|
N3 |
état |
status (état), status (fixé) |
2 |
|
N2 |
étroit(e) |
angusti, sténo |
2 |
|
N2 |
excrément |
copro, scato |
2 |
|
N1 |
fer |
ferro, sidéro |
2 |
|
N1 |
fleur |
antho, flore |
2 |
|
N1 |
forme |
forme, morpho |
2 |
|
N2 |
fruit |
carpo, fructi, frugi |
3 |
|
N2 |
génèse |
gène, poïèse |
2 |
|
N1 |
gouvernement |
arche, crate |
2 |
|
N2 |
graisse |
lipo, stéato |
2 |
|
N1 |
grandeur |
macro, mégalo |
2 |
|
N2 |
guider |
agogie : guider, duc |
2 |
|
N2 |
homme |
andro, anthropo, homo |
3 |
|
N2 |
identique |
homos, iso, tauto |
3 |
|
N1 |
lait |
gala, lacto |
2 |
|
N2 |
langue |
glosso, lingue |
2 |
|
N1 |
machine |
mécano, tron |
2 |
|
N2 |
main |
chiro, mane (manus) |
2 |
|
N2 |
maladie |
noso, patho (souffrance) |
2 |
|
N3 |
matrice |
hystéro, métro (mêtra) |
2 |
|
N1 |
mauvais(e) |
caco, mal |
2 |
|
N1 |
médecine |
iatre, thérapie |
2 |
|
N2 |
modification |
muta, trans : modification |
2 |
|
N1 |
moitié |
demi, mi, semi |
3 |
|
N2 |
mort |
morti, nécro, thanato |
3 |
|
N2 |
noyau |
caryo, nucléo |
2 |
|
N2 |
oeil |
oculo, ophtalmo |
2 |
|
N2 |
oeuf |
oion, ovum |
2 |
|
N2 |
or |
auri, chryso |
2 |
|
N1 |
parole |
logo, loquie |
2 |
|
N2 |
pesanteur |
baro, mano, piézo |
3 |
|
N1 |
petit(e) |
celle, cule, micro |
3 |
|
N1 |
peuple |
démo, ethno |
2 |
|
N2 |
pierre |
litho, pétro |
2 |
|
N3 |
poisson |
ichtyo, pisci |
2 |
|
N1 |
quatre |
quadri, quart, quater, tétra |
4 |
|
N3 |
rouge |
érythro, rubé |
2 |
|
N1 |
sans |
a, an, non |
3 |
|
N2 |
sens |
sémio, voque |
2 |
|
N1 |
son |
audio, sono |
2 |
|
N2 |
sucre |
gluco, glyco, saccharo |
3 |
|
N1 |
terre |
gée, géo, terra |
3 |
|
N2 |
tout(e) |
omni, toti |
2 |
|
N1 |
véhicule |
mobile, scaphe |
2 |
|
N2 |
vin |
œno, vino |
2 |
dactyle : doigt : digito <> dactyle : En fait le latin digitus provient du grec daktylos.
enaire : agé(e) : génaire <> enaire : Du latin -enarius, par ex. dans centenarius (centenaire) et du latin -genarius, par ex. dans quadragenarius (quadragénaire) : erreur ?
Concepts uniques
S'il existe des racines distinctes avec le même sens, alors cela signifie qu'il existe une liste des concepts uniques, on peut la consulter dans l'onglet Concept du classeur Excel : Logotron_fr.xls
Le dictionnaire des mots du français
J'ai trouvé la liste des mots fléchis du dictionnaire français ici :
http://infolingu.univ-mlv.fr/DonneesLinguistiques/Dictionnaires/telechargement.html
Je n'ai pas trouvé de liste de mot non fléchis (sans les verbes conjugués surtout, voir la rubrique ci-dessous).
Cette liste contient quelques mots un peu folkloriques, mais c'est la plus complète (près de 650 000) que j'ai pu trouver. J'ai juste corrigé quelques mots avec / (avec des l' notamment), dédoublonné et retrié la liste, supprimé les mots avec un espace (soit cent mille mots quand même, ex.: beau parleur), mais sinon, rien de plus. Ah si !, j'ai ajouté les 6664 mots fléchis qui sont dans le dictionnaire "frgut" et qui ne sont pas dans le DELA. Et inversement, voici les 300 mille mots fléchis du DELA qui n'étaient pas dans le frgut.
La langue française contient en tout 68 000 mots non fléchis :
https://fr.wiktionary.org/wiki/Wiktionnaire:Statistiques#Combien de mots en français ?
Pour le moment, je n'ai pas trouvé comment récupérer la liste des mots du Wiktionnaire.
Et puis après j'ai pensé à utiliser le dictionnaire de Libre Office :
Le dictionnaire de Libre Office
Le dictionnaire de Libre Office est géré par https://grammalecte.net/. Il sert à plusieurs outils à code source ouvert (open source), pas seulement Libre Office. Il est encodé de façon à pouvoir décliner toutes les variantes d'un mot à partir d'une racine commune (par exemple les pluriels, les féminins, ...). Du coup, pour obtenir la liste complète des mots déclinés, il faut un utilitaire dédié, lequel s'appelle "unmunch". On peut le trouver compilé ici : hunspell-1.3.2-3-w32-bin.zip. Le code source de unmuch est ici :
https://github.com/kscanne/hunspell-gd/blob/master/unmunch.sh
Mais ce code source est incomplet, plusieurs problèmes ont déjà été évoqués ici :
Improving
the tool for generating full list of words (unmunch/wordforms)
https://github.com/hunspell/hunspell/issues/404
En anglais, la syntaxe est la suivante :
unmunch
en_US.dic en_US.aff >> en_US.unmunched
unmunch en_GB.dic en_GB.aff >> en_GB.unmunched
Bizarrement, le fichier américain généré fait 20 Mo, tandis que celui britannique ne fait que 1.5 Mo !?
Encore plus bizarrement, unmunch ne fonctionne en français qu'en se trompant sur la syntaxe, il faut répéter deux fois le fichier .dic, lol !
unmunch fr-toutesvariantes.dic fr-toutesvariantes.dic >> fr-toutesvariantes.unmunched
(donc là je me suis trompé, mais il faut se tromper donc pour que ça marche !)
Donc effectivement, ça serait pas mal de terminer cet utilitaire (surtout ça serait bien de pouvoir retirer les verbes conjugués), mais j'ai quand même pu récupérer cette liste de mot en français, et ce qui est bien, c'est que la liste des mots propres est placée en début de fichier, ce qui fait qu'on peut facilement la retirer, comme dans notre cas. J'ai donc ajouté les mots du dictionnaire de Libre Office que je n'avais pas encore.
Le dictionnaire du Littré
Version 1.06 du 28/06/2020 : ajout du dictionnaire du Littré
Il est disponible ici (73192 mots) :
www.lama.univ-savoie.fr/pagesmembres/hyvernat/Enseignement/1314/info224/tp2.html#toc8
www.lama.univ-savoie.fr/pagesmembres/hyvernat/Enseignement/1314/info224/TP2/littre.txt
Nombre de mots ajoutés qui n'était pas dans le précédent dictionnaire :
On passe de 657009 à 681002 mots, soit 23993 mots ajoutés tout de même : Liste24KAjoutsDuLittre.txt
Nombre de mots qui n'était pas dans le dictionnaire du Littré : Pas facile à voir, car il faudrait retirer par exemple les verbes conjugués.
Les verbes conjugués
Comme je n'ai pas encore trouvé de dictionnaire des verbes conjugués, j'ai commencé à établir une liste d'exclusion : lorsque le mot envisagé se trouve dans cette liste, il est ignoré :
aplane, décèle, décentre, déchire, déchrome, décline, décolore, décoque, déculture, défère, déflore, déforme, dégrade, déloque, déparagée, déparasite, déprogramme, désiste, dévalent, dévore, décide, dépare, incère, incline, ingénie, invoque, permane, transite.
Le préfixe dé- signifie enlever. Si on considère par exemple le suffixe -chrome, il signifie couleur (comme dans polychrome, par exemple), par contre déchrome n'est pas un mot, mais la conjugaison du verbe déchromer à la 1ère personne.
Le préfixe per- signifie à travers / de part en part / terminer / intense (comme dans peroxyde par exemple : oxydation intense). Si on considère par exemple le suffixe -mane, il signifie main ou maniaque (comme dans quadrumane ou cleptomane, par exemple), par contre permane n'est pas un mot non plus, mais la conjugaison du verbe permaner (être permanent) à la 1ère personne.
http://patrice.dargenton.free.fr/CodesSources/Logotron/VerbesConjugues_fr.txt
Les sens multiples
Pour les segments ayant un sens multiple (comme -mane par exemple : main ou maniaque), une simple recherche dans le dictionnaire ne permet pas de trancher l'une ou l'autre des définitions. Une solution est donc de combiner toutes les définitions possibles, pour le ou les préfixes et le suffixe. Cependant une des options du quiz permet de partir de mots existants dans le dictionnaire, afin de retrouver la définition de son préfixe et de son suffixe (ou alors l'inverse : retrouver le préfixe et le suffixe correspondants à leur définitions). Dans ce cas il faut absolument s'en tenir à une définition unique et exacte des mots trouvés dans le dictionnaire. La solution que j'ai trouvé est la même que celle pour les verbes conjugués : une liste d'exclusion des définitions fausses. Ainsi, à chaque fois que l'on met à jour la liste des préfixes et suffixes, on exclura ces mots là :
http://patrice.dargenton.free.fr/CodesSources/Logotron/DefinitionsFausses_fr.txt
Voici un exemple :
cleptomane;MAIN DU VOL
cleptomane;MANIAQUE DU VOL
Ici -mane signifie maniaque, la définition fausse est donc main, on indique donc : cleptomane;MAIN DU VOL dans le fichier des définitions fausses.
Autre exemple :
mélomane;MAIN DU CHANT
mélomane;MAIN DU MEMBRE
mélomane;MANIAQUE DU CHANT
mélomane;MANIAQUE DU MEMBRE
Ici -mane signifie maniaque (ou admirateur, adorateur, amateur), et mélo- signifie le chant (comme dans mélodie, cela vient du grec ancien μέλος, mélos : membre de phrase musicale ou membre anatomique), donc la seule définition juste est : mélomane;MANIAQUE DU CHANT, et toutes les autres sont fausses.
Avec les suffixes -pathe et -pathie, il n'y a que quelques mots dont la définition correspond au ressenti plutôt qu'à la maladie. Au lieu d'indiquer la bonne définition pour chacun des nombreux mots correspondant à la maladie, il est plus judicieux cette fois d'indiquer dans une colonne spécifique du classeur Excel, la colonne "Exclusivité", la liste des mots pour lequel la variante de sens du suffixe (ou du préfixe) s'applique de façon exclusive : télépathie, sympathie, antipathie, apathie.
De même pour le préfixe pédo- avec le sens de "sol" et non "enfant" : pédofaune, pédoflore, pédogenèse, pédogénétique, pédologie, pédologique, pédologue, pédomètre.
Un dernier exemple avec le suffixe -gramme pour le sens du poids, plutôt que le sens "écriture" (comme dans télégramme) : centigramme, décagramme, décigramme, hectogramme, kilogramme, microgramme, milligramme, nanogramme.
Mise à jour du 13/07/2020 : Lorsque le préfixe n'est pas en première position, on doit maintenant préciser sa position dans cette liste de définitions exclusives, exemple avec gram- : aérophotogrammétrique:3, kilogrammètre:2, photogrammètre:2, photogrammétrie:2, photogrammétrique:2
Note : Il peut rester quelques définitions fausses ou imprécises parmi la liste des 4000 mots simples trouvés dans le dictionnaire, le quiz n'est pas fiable à 100 % (on peut toujours améliorer les définitions proposées, ou sinon retirer une définition, mais il est parfois difficile de trouver une définition valable pour l'ensemble des mots contenant le préfixe et le suffixe).
Les mots du type Logotron trouvés dans le dictionnaire français
Les mots avec un préfixe et un suffixe
Voici la liste de tous les mots existants du dictionnaire que l'on peut former avec un préfixe et un suffixe, il y en a plus de 7000 (dont 5500 avec des racines distinctes pour les préfixes et suffixes), cette liste va servir à l'une des deux options du quiz :
http://patrice.dargenton.free.fr/CodesSources/Logotron/MotsSimples_fr.txt
Les mots avec des préfixes multiples et un suffixe
Voici la liste de tous les mots complexes existants du dictionnaire que l'on peut former avec des préfixes et un suffixe, il y en a plus de 2400 :
http://patrice.dargenton.free.fr/CodesSources/Logotron/MotsComplexes_fr.txt
Les mots avec un ou plusieurs préfixes et un suffixe
Voici la liste de tous les mots existants du dictionnaire que l'on peut former avec un ou plusieurs préfixes et un suffixe, il y en a près de 10 000, soit 14% des 73 000 mots du dictionnaire :
http://patrice.dargenton.free.fr/CodesSources/Logotron/Mots_fr.txt
Classement des préfixes et suffixes par niveau de difficulté
On peut classer les préfixes et les suffixes par niveau de difficulté : 1 : facile (ex.: cardio-, -drome, -phile, -logue, -phage), 2 : moyen (ex.: hépato-, géronto-, -céphale, -pithèque) et 3 : difficile (ex.: ana-, tribo-, xantho-, -gnathe). Le niveau de difficulté sert bien sûr principalement pour le quiz, mais aussi pour le Logotron, pour générer des mots simples ou bien difficiles. Le niveau de difficulté est unique au niveau de la racine (tous les préfixes d'une même racine doivent avoir un niveau identique, pareil pour les suffixes, pour justement faciliter l'ajout de préfixes et suffixes tout en restant assez cohérent, sinon un avertissement sera affiché, si on clique sur le bouton Avert.).
Analyse de la complexité des mots
On peut calculer une sorte de complexité du mot via le niveau de difficulté du ou des préfixes et du suffixe le composant. Le calcul qui permet de prendre en compte cela consiste simplement à multiplier le niveau du ou des préfixes +1, avec le niveau du suffixe +1, exemples :
4 : aérodrome : 2 : aéro(1) - drome(1) : PISTE DE L'AIR
aéro- et -drome sont tous deux des segments simples, de niveau 1 donc, (1+1)x(1+1) = 4, la complexité du mot ainsi formé est très simple : 4
108 : polyangionévrite : 4 : poly(2) - angio(3) - névr(2) - ite(2) : INFLAMMATION MULTIPLE DU VAISSEAU DU NERF(2+1)x(2+1)x(2+1)x(3+1) = 108
Voici le tri par complexité croissante de tous les mots existants du dictionnaire que l'on peut former avec un ou plusieurs préfixes et un suffixe :
http://patrice.dargenton.free.fr/CodesSources/Logotron/Complexite_fr.txt
Analyse de la fréquence des mots
Cette étape permet de déterminer les fréquences des préfixes et suffixes depuis les mots existants du dictionnaire. Si le préfixe ou suffixe est utilisé plus de 20 fois dans les mots trouvés, il est fréquent, et il est rare s'il est utilisé moins de 5 fois. Cette fréquence est donc seulement la fréquence relative à l'utilisation d'un segment parmi la liste des mots logotroniques, elle ne tient pas compte de la fréquence effective du mot dans la langue française. Cette dernière fréquence peut se calculer dans un corpus document suffisamment grand, une encyclopédie par exemple. Comme il y a certainement une corrélation élevée entre la faible fréquence et la difficulté, le filtre sur la fréquence serait plus pertinent en tant que niveau de difficulté supplémentaire du quiz. Par exemple, poïèse (« action de faire », « création ») est un suffixe déterminé comme fréquent car 21 mots ont été trouvés, alors que ces mots ne sont pas fréquents dans le langage courant : cholépoïèse, dysérythropoïèse, dyshématopoïèse, dyshémopoïèse, dysmyélopoïèse, écopoïèse, érythropoïèse, hématopoïèse, hémopoïèse, histopoïèse, leucopoïèse, lymphocytopoïèse, lymphopoïèse, mégacaryocytopoïèse, monocytopoïèse, myélopoïèse, thrombocytopoïèse, thrombopoïèse, uréopoïèse, uricopoïèse, uropoïèse.
Fichier bilan
Lors de l'analyse des mots du dictionnaire, un fichier bilan DicoLogotron\Doc\BilanDico_fr.txt est généré, voici son contenu :
Segments à sens multiple
Lorsqu'un segment a de multiple sens, on décompte les mots trouvés pour chaque sens, dans l'idée que si un sens est très peu utilisé par rapport à un autre sens usuel, alors il est avantageux de spécifier une liste exclusive de mots pour lequel ce sens est valide, cela évite en effet d'avoir à renseigner les définitions fausses pour chaque combinaison. Par exemple, pour le segment -pathie avec le sens "ressenti", on ne trouve que quatre mots correspondants : antipathie, apathie, sympathie, télépathie. Du coup, -pathie avec le sens "maladie" pourra être utilisé avec tous les autres mots.
Préfixes fréquents
Ce rapport liste les préfixes les plus fréquents trouvés dans le dictionnaire, notamment en premier les composables, c'est-à-dire ceux avec lesquelles on a pu trouver aussi un suffixe existant.
Suffixes fréquents
Même chose pour les suffixes fréquents.
Définitions incomplètes
Les définitions incomplètes forment une liste des mots du dictionnaire dont on a pu trouver quelques correspondances avec des préfixes et suffixes existants, mais pas complètement. Par exemple : photosensibilisation : ACTION DE LA LUMIÈRE : photo - ation : 10 < 20 : manque sensibilis : sensibilis- n'est pas un préfixe répertorié.
L'idée de cette liste est de trouver des préfixes et des suffixes qu'il serait intéressant d'ajouter pour pouvoir définir de nouveaux mots.
Mots avec préfixe(s) et suffixe
Voir la rubrique correspondante.
Mots avec des préfixes multiples et un suffixe
Voir la rubrique correspondante.
Mots avec préfixe et suffixe
Voir la rubrique correspondante.
Préfixes manquants fréquents
Ce sont les préfixes potentiels que l'on trouve le plus souvent, donc ceux qui sont les plus intéressants à ajouter dans la liste.
Tri des mots par complexité
Voir la rubrique correspondante.
Préfixes et suffixes potentiels
Un rapport est également généré avec des préfixes et suffixes potentiels, il s'agit de deux listes formées à partir de la liste du Dr Aly Abbara (mais sans les définitions). L'idée de ce rapport est toujours la même, à savoir trouver des préfixes et suffixes qu'il serait intéressant d'ajouter, mais cette fois avec une définition (et une étymologie de préférence).
Modélisation des données
Lorsque l'on analyse le contenu du classeur Logotron_fr.xls, on constate une certaine redondance des données, par exemple pour l'étymologie, qui est quasiment toujours la même pour une racine donnée. La modélisation des données consiste justement à représenter l'ensemble des données avec un minimum d'information, sans redondance. La première étape pour y arriver consiste à normaliser le sens des concepts de façon à rassembler ceux qui ne représentent que de légères variantes de sens, par exemple phago- et -phagie (mangé(e) / qui mange, mangeur, manger, alimentation). Ici, on voit bien que le choix des variantes de sens n'a eu que pour objectif de correctement définir les mots formés par chacun des segments (de façon automatique), mais au fond le sens de la racine phago est exactement la même dans tous les cas. Au final on obtient (Logotron_fr.mdb) :
- Une liste de 563 concepts, avec un nombre de racines pour chacun variant de 1 à 4 ;
- Une liste de 653 racines reliées à un concept unique, avec l'étymologie, l'origine, le niveau de difficulté. Le sens de la racine n'est précisé que s'il n'est pas exactement celui du concept lié ;
- Une liste de 770 segments reliés à une racine unique, avec des variantes orthographiques légères. L'étymologie du segment n'est précisée que si elle n'est pas exactement celle de la racine liée, pareil pour le sens et l'origine, et de même pour les tables Préfixe et Suffixe ;
- Une liste de 739 préfixes reliés à un segment unique, avec des exemples de mots trouvés dans le dictionnaire, ou alors une liste exclusive de mots pour lesquels ce préfixe peut être utilisé ;
- Une liste de 411 suffixes reliés à un segment unique, avec des exemples de mots trouvés dans le dictionnaire, ou alors une liste exclusive de mots pour lesquels ce suffixe peut être utilisé.
Ces listes correspondent exactement à ce qu'on trouve dans le classeur Excel (si l'on exclut les segments non sélectionnés, avec la colonne B à 0), sauf que cette fois, il n'y a pas de redondance sur les champs étymologie, origine, sens et niveau.
Un fichier Bilan est généré (Bilan_fr.txt) pour indiquer les cas spécifiques, lorsque par exemple pour un segment donné l'étymologie est précisée par rapport à l'étymologie générale de la racine.
Un fichier json est généré (LogotronBdd_fr.json) pour faciliter les comparaisons lorsque le logiciel est modifié, et un autre est généré (LogotronBddIdTxt_fr.json) pour faciliter les comparaisons lorsque des préfixes et suffixes sont ajoutés dans le classeur Excel, en évitant les identifiants numériques, pour lesquels toute comparaison de version serait fastidieuse (des identifiants sous forme texte, moins lisibles mais plus stables, sont utilisés à la place).
Voici le plan de la base de données générée et remplie par le code (mode "code first") :
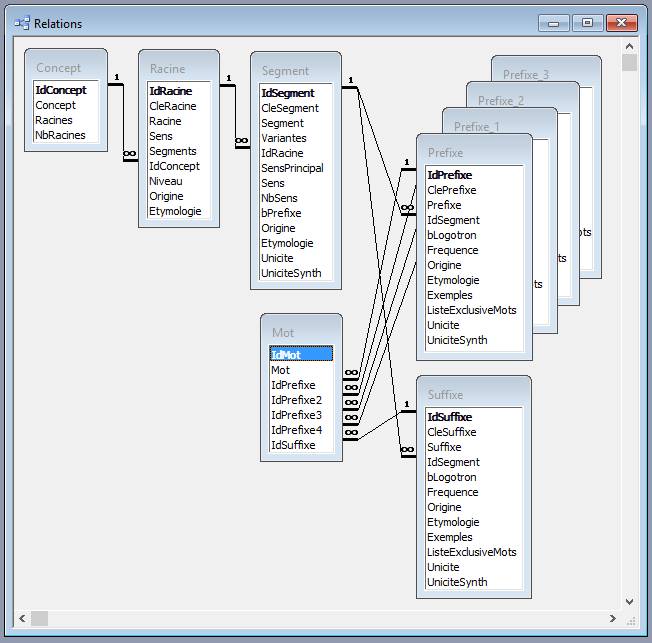
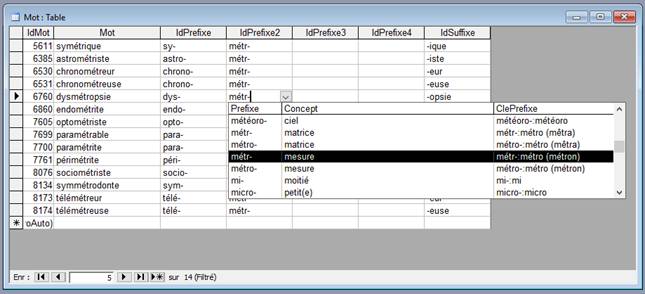
Voici un exemple de recherche sous MS-Access avec les filtres sur les préfixes et suffixes :
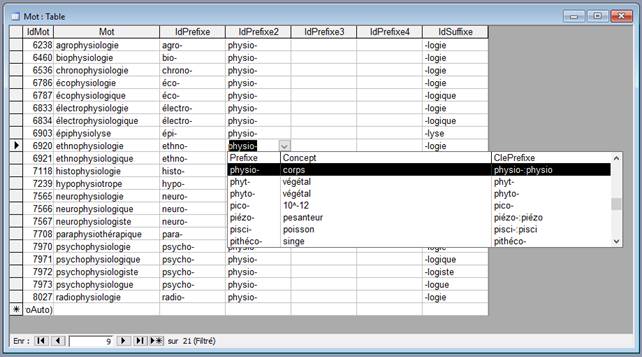
Voici un autre exemple de recherche :
Voici le rapport DBComp sur la structure de la base de données :
Rapport
de base de données DBComp :
Base
de données : Logotron_fr.mdb
Concept
: Table des concepts
IdConcept (Long) : Identifiant du concept
(Null interdit)
Concept (Text50) : Sens du concept (Null
interdit)
Racines (Text255) : Liste des racines
associées (Null interdit)
NbRacines (Long) : Nombre de racines
associées (Null interdit)
Index
: IX_Concept, Unique
champ : Concept
Index
: PK_Concept_ba10e5e8, Unique, Primary
champ : IdConcept
Mot
: Table des mots
IdMot (Long) : Identifiant du mot (Null
interdit)
Mot (Text50) : Mot (Null interdit)
IdPrefixe (Long) : Identifiant du préfixe
formant le mot (Null interdit)
IdPrefixe2 (Long) : Identifiant du préfixe
n°2 formant le mot
IdPrefixe3 (Long) : Identifiant du préfixe
n°3 formant le mot
IdPrefixe4 (Long) : Identifiant du préfixe
n°4 formant le mot
IdSuffixe (Long) : Identifiant du suffixe
formant le mot (Null interdit)
Index
: IX_IdPrefixe
champ : IdPrefixe
Index
: IX_IdPrefixe2
champ : IdPrefixe2
Index
: IX_IdPrefixe3
champ : IdPrefixe3
Index
: IX_IdPrefixe4
champ : IdPrefixe4
Index
: IX_IdSuffixe
champ : IdSuffixe
Index
: Mot, Unique
champ : Mot
Index
: PK_Mot_ba10e5e8, Unique, Primary
champ : IdMot
Prefixe
: Table des préfixes
IdPrefixe (Long) : Identifiant du préfixe
(Null interdit)
ClePrefixe (Text50) : Clé unique du préfixe
(Null interdit)
Prefixe (Text50) : Préfixe (Null interdit)
IdSegment (Long) : Identifiant du segment
d'origine (Null interdit)
bLogotron (Boolean) : Booléen indiquant si le
préfixe est compatible avec le Logotron (ou sinon si le préfixe sert pour
l'analyse du dictionnaire) (Null interdit)
Frequence (Text50) : Fréquence du préfixe
parmi les mots 'Logotroniques' (Null interdit)
Origine (Text50) : Origine étymologique
spécifique du préfixe, si elle est différente de celle du segment ou de la
racine
Etymologie (Memo) : Etymologique spécifique
du préfixe, si elle est différente de celle du segment ou de la racine
Exemples (Text255) : Exemple(s) de mot(s)
formé(s) avec ce préfixe
ListeExclusiveMots (Memo) : Liste exclusive
de mots pouvant être formés avec ce préfixe
Unicite (Text50) : Unicité du préfixe (pour
regrouper les préfixes relatifs à un même segment, si besoin est)
UniciteSynth (Text50) : Unicité explicite du
préfixe (pour regrouper les préfixes relatifs à un même segment) (Null
interdit)
Index
: IX_bLogotron
champ : bLogotron
Index
: IX_ClePrefixe, Unique
champ : ClePrefixe
Index
: IX_IdSegment
champ : IdSegment
Index
: IX_Origine
champ : Origine
Index
: IX_Prefixe
champ : Prefixe
Index
: IX_UniciteSynth
champ : UniciteSynth
Index
: PK_Prefixe_ba10e5e8, Unique, Primary
champ : IdPrefixe
Racine
: Table des racines
IdRacine (Long) : Identifiant de la racine
(Null interdit)
CleRacine (Text50) : Clé unique de la racine
(Null interdit)
Racine (Text50) : Racine principale
(représentative) (Null interdit)
Sens (Text100) : Sens spécifique de la
racine, s'il est nuancé par rapport au sens du concept
Segments (Text255) : Liste des segments
associés (Null interdit)
IdConcept (Long) : Identifiant du concept
d'origine (Null interdit)
Niveau (Integer) : Niveau de difficulté de la
racine (Null interdit)
Origine (Text50) : Origine étymologique de la
racine
Etymologie (Memo) : Etymologie de la racine
Index
: IX_CleRacine, Unique
champ : CleRacine
Index
: IX_IdConcept
champ : IdConcept
Index
: IX_Niveau
champ : Niveau
Index
: IX_Origine
champ : Origine
Index
: IX_Racine, Unique
champ : Racine
Index
: IX_Sens
champ : Sens
Index
: PK_Racine_ba10e5e8, Unique, Primary
champ : IdRacine
Segment
: Table des segments
IdSegment (Long) : Identifiant du segment
(Null interdit)
CleSegment (Text50) : Clé unique du segment
(Null interdit)
Segment (Text50) : Segment (Null interdit)
Variantes (Text255) : Variantes du segment
(Null interdit)
IdRacine (Long) : Identifiant de la racine
d'origine (Null interdit)
SensPrincipal (Text100) : Sens principal du
segment (Null interdit)
Sens (Text255) : Sens spécifique du segment,
s'il est nuancé par rapport au sens de la racine ou du concept
NbSens (Long) : Nombre de sens répertoriés
(Null interdit)
bPrefixe (Boolean) : Booléen indiquant si le
segment correspond à des préfixes (ou sinon des suffixes) (Null interdit)
Origine (Text50) : Origine étymologique
spécifique du segment, si elle est différente de celle de la racine
Etymologie (Memo) : Etymologique spécifique
du segment, si elle est différente de celle de la racine
Unicite (Text50) : Unicité du segment (pour
distinguer les préfixes ou suffixes, si besoin est)
UniciteSynth (Text50) : Unicité explicite du
segment (pour distinguer les préfixes ou suffixes) (Null interdit)
Index
: IX_bPrefixe
champ : bPrefixe
Index
: IX_CleSegment, Unique
champ : CleSegment
Index
: IX_IdRacine
champ : IdRacine
Index
: IX_Origine
champ : Origine
Index
: IX_UniciteSynth
champ : UniciteSynth
Index
: PK_Segment_ba10e5e8, Unique, Primary
champ : IdSegment
Suffixe
: Table des suffixes
IdSuffixe (Long) : Identifiant du suffixe
(Null interdit)
CleSuffixe (Text50) : Clé unique du suffixe
(Null interdit)
Suffixe (Text50) : Suffixe (Null interdit)
IdSegment (Long) : Identifiant du segment
d'origine (Null interdit)
bLogotron (Boolean) : Booléen indiquant si le
suffixe est compatible avec le Logotron (ou sinon si le suffixe sert pour
l'analyse du dictionnaire) (Null interdit)
Frequence (Text50) : Fréquence du suffixe
parmi les mots 'Logotroniques' (Null interdit)
Origine (Text50) : Origine étymologique
spécifique du suffixe, si elle est différente de celle du segment ou de la
racine
Etymologie (Memo) : Etymologique spécifique
du suffixe, si elle est différente de celle du segment ou de la racine
Exemples (Text255) : Exemple(s) de mot(s)
formé(s) avec ce suffixe
ListeExclusiveMots (Memo) : Liste exclusive
de mots pouvant être formés avec ce suffixe
Unicite (Text50) : Unicité du suffixe (pour
regrouper les suffixes relatifs à un même segment, si besoin est)
UniciteSynth (Text50) : Unicité explicite du
suffixe (pour regrouper les suffixes relatifs à un même segment) (Null
interdit)
Index
: IX_bLogotron
champ : bLogotron
Index
: IX_CleSuffixe, Unique
champ : CleSuffixe
Index
: IX_IdSegment
champ : IdSegment
Index
: IX_Origine
champ : Origine
Index
: IX_Suffixe
champ : Suffixe
Index
: IX_UniciteSynth
champ : UniciteSynth
Index
: PK_Suffixe_ba10e5e8, Unique, Primary
champ : IdSuffixe
Cycle de vie des données
Le cycle de vie des données est le suivant :
1°) Modifier le classeur Excel Logotron_fr.xls
2°) Convertir le classeur en csv : Logotron_fr.csv (via XL2Csv par exemple)
3°) Lancer Logotron.exe (en VB .Net), en mode de lecture csv (src\_modConst.sModeLecture = enumModeLecture.sCsv) les fichiers de préfixes et suffixes sont générés sous différents formats (csv, code et json) via la fonction TraiterEtExporterDonnees à partir du fichier Logotron_fr.csv
4°) Lancer DicoLogotron\DicoLogotron.exe et cliquer sur le bouton Dico, le fichier DicoLogotron\Doc\MotsSimples_fr.csv est généré, le recopier dans MotsSimples_fr.csv (à la racine du projet) et dans CSharp\WinForm\MotsSimples_fr.csv
5°) Pour les versions en C#, il n'y a pas encore de lecture json ni csv (sauf les mots en C# WinForm), il faut copier/coller le code dans CSharp\LogotronLib\Src\ : clsListeMotsExistants.cs, clsListePrefixes.cs et clsListeSuffixes.cs depuis respectivement DicoLogotron\Doc\MotsSimplesCode_fr.txt et PrefixesSuffixes2.txt (contient les deux listes)
6°) Lancer DicoLogotron\DicoLogotron.exe et cliquer sur le bouton Fréq. pour analyser la fréquence des préfixes et suffixes dans les mots du dictionnaire, le fichier DicoLogotron\Doc\Stats_fr.csv est généré. Convertir ce fichier .csv en .xls via File2XL (si on ouvre directement avec Excel, le tiret devant le suffixe est confondu avec le signe - des formules, et ça ne marche pas du coup). Ensuite faire un copié/collé des données dans l'onglet Frequence du fichier Logotron_fr.xls, et reprendre à l'étape 1°).
A différentes étapes, des avertissements peuvent être générés, par exemple pour l'étape n°3, en cliquant sur le bouton Avert., on détecte par exemple les segments qui ne commencent pas par la même lettre, les racines multiples, ainsi que les racines ayant un niveau différent :
Racines : Segment ne commençant pas par
la même lettre : contra- <> anto : contre
Racines : Segment ne commençant pas par
la même lettre : kérat- <> cérato : cornée
Racines : Segment ne commençant pas par
la même lettre : kérato- <> cérato : cornée
Racines : Segment ne commençant pas par
la même lettre : -kinèse <> ciné : mouvement
Racines : Segment ne commençant pas par
la même lettre : kinési- <> ciné : mouvement
Racines : Segment ne commençant pas par
la même lettre : -kinésie <> ciné : mouvement
Racines : Segment ne commençant pas par
la même lettre : kinésio- <> ciné : mouvement
Racines : Segment ne commençant pas par
la même lettre : -urge <> erg : travail
Racines : Segment ne commençant pas par
la même lettre : -urgie <> erg : travail
Racines : Segment ne commençant pas par
la même lettre : -urgique <> erg : travail
Racines : Segment ne commençant pas par
la même lettre : -oïde <> forme : forme
Racines : Segment ne commençant pas par
la même lettre : inter- <> entre : entre
Racines : Segment ne commençant pas par
la même lettre : -tude <> itude : qualité / état
Racines : Segment ne commençant pas par
la même lettre : -nymie <> onyma : nom
Racines : Segment ne commençant pas par
la même lettre : -ïde <> phéno : apparence
Pour éviter un avertissement pour un sens de racine multiple, il faut renseigner une unicité distincte dans la colonne Unicité du classeur Excel Logotron_fr.xls.
Lors de l'étape n°4, on détecte par exemple les doublons de sens possible pour les mots simples (un préfixe et un suffixe) : s'il y a plusieurs sens, alors le mot ne peut plus être utilisé pour le quiz (les mots logotroniques n'ont qu'un seul sens dans le dictionnaire, a priori). Pour éviter les doublons, on doit renseigner les définitions erronées dans le fichier DicoLogotron\Doc\DefinitionsFausses_fr.txt et relancer l'étape n°4. On peut aussi éliminer les sens erronés des mots avec un seul sens trouvé, lorsqu'il ne correspond pas à sa définition logique (automatique).
Avec le modèle de base de données, on peut rajouter une étape dans le cycle de vie de données, pour s'assurer que la modification des données est bien cohérente, par exemple en comparant le fichier LogotronBddIdTxt_fr.json avec une version précédente. Il suffit juste de copier le nouveau fichier DicoLogotron\Doc\MotsComplexesUnicite_fr.txt dans le dossier CSharp\DicoLogotronMdb et de relancer l'application DicoLogotronMdb en mode Release sous Visual Studio 2017, ou sinon de lancer directement l'exécutable CSharp\DicoLogotronMdb\bin\Release\DicoLogotronMdb.exe avec le fichier MotsComplexesUnicite_fr.txt à jour. Si certains préfixes ou suffixes ne sont pas trouvés lors de l'analyse des mots du dictionnaire (cf. Bilan_fr.txt), c'est que soit les données ne sont pas à jour (liste des préfixes et suffixes dans le code source en C#), soit qu'il reste des définitions fausses à renseigner (il ne doit subsister aucun doublon dans le sens des mots simples et complexes). Eventuellement, il pourrait s'agir aussi d'une erreur de segmentation des mots (cf. DicoLogotron en VB .Net), avec un cas qui n'aurait pas encore été prévu.
Le Logotron en Bridge React
La version en ligne du Logotron est codée en Bridge React, avec Visual Studio 2017. React est le langage de développement popularisé par Facebook pour concevoir des applications web monopage. Bridge est une technologie permettant de convertir du code C# en JavaScript, l'idée étant de récupérer les compétences acquises en DotNet pour programmer pour le web. Il existe déjà des milliers de librairies JavaScript adaptées en .Net.
Je suis parti de l'excellent tutoriel en trois parties de Dan Roberts, et j'ai mixé mon code avec le tutoriel officiel afin de pouvoir bénéficier de toutes les options de débogage en C# dans le navigateur : pause, pause sur exception, pas à pas, état des variables, de la pile d'appel, ... (options qui ne marchaient pas dans le tuto de départ)
J'ai fait une version Release et une version Debug, car en mode Release ça prend du temps à compiler (il faut cependant compiler une première fois en mode Release pour activer la conversion du code en Javascript). En effet, comme je n'ai pas réussi à lire un fichier csv ou json en Bridge React, j'ai inséré directement la liste des mots du dictionnaire pour le quiz via le code, la liste étant générée depuis la version en VB .Net.
Si on met à jour toutes les librairies NuGet, ou partiellement, on obtient des erreurs, soit à la compilation, soit à l'exécution, selon les cas. Pour le moment, on ne peut donc pas utiliser les dernières librairies disponibles.
Si le fichier JavaScript n'est plus généré à l'issue de la compilation, c'est parce que le fichier CSharp\Bridge.React\Bridge.React\bridge.json a été remplacé lors de l'installation d'une mise à jour, et que la ligne suivante ne fonctionne pas : "output": "$(OutDir)/bridge/",
Il faut rétablir le json qui marche dans ce cas : "output": "js",
J'ai pas mal galéré concernant le cycle de vie des variables selon le paradigme de React, lequel consiste à virtualiser le DOM du navigateur, je ne garantis pas que mon code suit l'état de l'art de la programmation en React, mais j'ai suivi le plus possible les recommandations des tutoriels, et cela fonctionne plutôt pas mal (si on clique trop vite sur le quiz, les préfixes et suffixes s'ajoutent dans les listes si on augmente un peu la temporisation de la tâche d'attente !). Toutefois, je n'en suis pas encore à être complètement satisfait du code : par exemple, je n'ai pas réussi à faire un composant ScrollTextBox valable en Bridge React, alors que le même composant réalisé en React standard par un développeur compétent n'a pris que quelques minutes à le réaliser, et il est parfait (excepté que sur iOS, la sélection du dernier mot ne fonctionne pas). Et je n'ai pas réussi non plus à enchainer la question suivante du quiz lorsque le choix est correct ! Mais bon, c'est ma première application web, et c'est déjà pas mal. Pour le moment, l'intérêt de faire du .Net pour le web n'est pas flagrant, sauf pour la partie récupération du code métier en dehors de l'interface (ici le moteur du Logotron). Par contre, pour la partie interface, ce n'est pas franchement plus simple de coder en C#, et il est difficile de trouver de l'aide sur le web, car c'est une technologie avant-gardiste pour le moment. Mais l'avantage c'est que le typage fort du C# va quand même beaucoup plus loin que celui de TypeScript : au lieu d'ajouter une surcouche de typage à JavaScript, autant ajouter une étape de transpilation de C# vers JavaScript, c'est quand même plus classe, surtout pour détecter un maximum de problème lors de la compilation, et non lors de l'exécution. Il me reste à tester d'autres librairies pour voir tout ce qu'on peut faire avec cette techno Bridge.
Projets
- Quiz sur les mots existants : au lieu d'un seul préfixe, faire le quiz sur les mots plus complexes, avec 2, 3 ou plus de préfixes. Quiz aussi sur les mots avec soit un préfixe, soit un suffixe ;
- Quiz : mémorisation du score en ligne, et partage des meilleurs scores avec les autres joueurs ;
- Quiz sur les mots existants : filtre sur un métier associé aux mots (via une feuille Excel) : médecine, géologie, ...
- Version tablette et mobile (sur iOS en web, les zones de liste des préfixes et suffixes apparaissent sous forme de combobox au lieu des listbox attendues, ce qui n'est vraiment pas pratique : c'est injouable) ;
- Fréquence d'une racine : voir comment on peut la trouver ou la calculer en tenant compte de la fréquence effective des mots du dictionnaire dans la langue française, en recherchant dans un corpus documentaire représentatif ;
- Zone de recherche : dans la liste des mots existants, rechercher les mots qui correspondent (à un préfixe, un suffixe, ou n'importe quelle combinaison de lettres).
Autres langues
Le principe du Logotron pourrait aussi fonctionner dans une autre langue, par exemple en anglais, mais l'orthographe ne sera pas exactement identique, et le sens et l'étymologie devra aussi être traduit : est-ce intéressant de partir sur une liste commune entre toutes les langues ? (Apparemment oui car c'est la solution qui est retenue pour le Wiktionnaire, mais cette solution a été appliquée pour chaque langue !)
Si par exemple on ajoute seulement les préfixes et suffixes suivants :
|
Racine |
Préfixe |
Suffixe |
Sens |
Etymologie |
Exemples |
|
bio |
bio- |
|
life |
From Ancient Greek βίος (bíos, “bio-, life”). |
biology |
|
logy |
|
-logy |
study |
From Ancient Greek -λογία (-logía, “-logy, branch of study, to speak”). |
biology |
|
phone |
|
-phone |
voice |
From Ancient Greek φωνή (phōnḗ, “voice, sound”). |
telephone |
|
scope |
|
-scope |
look at |
From Ancient Greek σκοπέω (skopéō, “I look at”). |
telescope |
|
tele |
tele- |
|
afar |
From Ancient Greek τῆλε (têle, “afar”). |
telephone, telescope |
On peut former les concepts suivants :
|
Concepts |
Racines |
|
afar |
tele |
|
life |
bio |
|
look at |
scope |
|
study |
logy |
|
voice |
phone |
Et les racines suivantes :
|
Racine |
Sens |
Déclinaisons et variantes |
|
bio |
life |
bio- |
|
logy |
study |
-logy |
|
phone |
voice |
-phone |
|
scope |
look at |
-scope |
|
tele |
afar |
tele- |
Et les segments suivants :
|
Racine |
Segment |
Sens |
|
bio |
bio- |
life |
|
logy |
-logy |
study |
|
phone |
-phone |
voice |
|
scope |
-scope |
look at |
|
tele |
tele- |
afar |
On peut trouver les mots suivants dans le dictionnaire anglais :
bio : LIFE
: bio-
logy :
STUDY : -logy
phone :
VOICE : -phone
scope :
LOOK AT : -scope
biology :
STUDY LIFE : bio - logy
bioscope :
LOOK AT LIFE : bio - scope
telephone :
VOICE AFAR : tele - phone
telescope :
LOOK AT AFAR : tele - scope
Et on peut former les mots nouveaux suivants :
TELELOGY
STUDY AFAR
TELE(1) -
LOGY(1)
tele- :
From Ancient Greek τῆλε (têle, “afar”).
-logy :
From Ancient Greek -λογία (-logía, “-logy, branch of study, to speak”).
BIOPHONE
VOICE LIFE
BIO(1) -
PHONE(1)
bio- : From
Ancient Greek βίος (bíos, “bio-, life”).
-phone :
From Ancient Greek φωνή (phōnḗ, “voice, sound”).
BIOTELEPHONE
VOICE LIFE
AFAR
BIO(1) -
TELE(1) - PHONE(1)
bio- : From
Ancient Greek βίος (bíos, “bio-, life”).
tele- :
From Ancient Greek τῆλε (têle, “afar”).
-phone :
From Ancient Greek φωνή (phōnḗ, “voice, sound”).
BIOTELESCOPE
LOOK AT
LIFE AFAR
BIO(1) -
TELE(1) - SCOPE(1)
bio- : From
Ancient Greek βίος (bíos, “bio-, life”).
tele- :
From Ancient Greek τῆλε (têle, “afar”).
-scope :
From Ancient Greek σκοπέω (skopéō, “I look at”).
TELEBIOPHONE
VOICE AFAR
LIFE
TELE(1) -
BIO(1) - PHONE(1)
tele- :
From Ancient Greek τῆλε (têle, “afar”).
bio- : From
Ancient Greek βίος (bíos, “bio-, life”).
-phone :
From Ancient Greek φωνή (phōnḗ, “voice, sound”).
BIOSCOPE
LOOK AT
LIFE
BIO(1) -
SCOPE(1)
bio- : From
Ancient Greek βίος (bíos, “bio-, life”).
-scope :
From Ancient Greek σκοπέω (skopéō, “I look at”).
BIOTELESCOPE
LOOK AT
LIFE AFAR
BIO(1) -
TELE(1) - SCOPE(1)
bio- : From
Ancient Greek βίος (bíos, “bio-, life”).
tele- :
From Ancient Greek τῆλε (têle, “afar”).
-scope :
From Ancient Greek σκοπέω (skopéō, “I look at”).
Voici un point de départ pour compléter les préfixes et suffixes en anglais :
- Wiktionary:
Appendix:English prefixes
https://en.wiktionary.org/wiki/Appendix:English_prefixes
- Wiktionary:
Appendix:English suffixes
https://en.wiktionary.org/wiki/Appendix:English
suffixe
Les corrections de la liste d'origine des préfixes et suffixes
Par rapport à la première version (de J.-P.P.) du Logotron, voici les corrections que j'ai faites :
Note : Pour voir toutes les corrections et ajouts, on peut comparer les fichiers PrefixesSuffixesOrig.txt et PrefixesSuffixes.txt)
Préfixes
Corrections :
ankilo- --> ankylo : ankyl-, ankylo- : resserré et indiquant une gêne, une imperforation, une adhérence, une soudure
choréo- : la danse --> choré- (ex.: chorégraphie)
cinémato- : le cinéma --> le mouvement (ou cinét- comme dans cinétique)
éco- : la maison (domestique) --> la maison -> l'écologie / l'économie (nouveaux sens par extension)
érotico- : l'érotisme --> éro- : le désir et éroto- : l'érotisme
ichto- --> ichtyo- : le poisson
méta- : (introspection) --> au-delà / après
myxo- : le rhume --> le mucus : relatif au mucus, à une muqueuse (tissu mou humecté de mucus)
oligo- : trop petit(e) --> parcimonieux (-euse) : peu abondant
oxydo- : l'oxygène (acide) --> l'oxygène / l'acide
phréno- : le cerveau --> l'esprit
pseudo- : factice --> presque
stéréo- : dans l'espace (solide) --> solide -> robuste / le relief
stylo- : le bâton --> la colonne
sidéro- : le ciel --> sidéro- : le fer, et aussi : sidér- : l'astre, le fer
Ajouts de sens :
chloro- : vert, et aussi maintenant chloré : qui contient du chlore
eu- : bien, et aussi : véritable (et pour la seule analyse du dictionnaire, plus pour le Logotron)
pan- : de tout, et aussi : panto-, pant-
xéno- : l'étranger --> l'étranger / l'hôte
Variantes orthographiques :
bi- : double : bis- aussi (ex.: bisaïeul)
tri- : triple : tris- aussi (ex.: trisaïeul)
calli- : beau (belle), mais aussi calo- : beau (belle)
Doublons retirés :
metro- : la mesure
Suffixes
Corrections :
-centrisme : être centré autour --> centrage
-chronique : répétition --> temporel(le) (ex.: anachronique, chronique, diachronique, isochronique, synchronique)
-cope : choc (comme dans syn-cope ?) --> qui coupe (ex.: xylocope : qui coupe du bois)
-crate : pouvoir --> gouverneur (et -cratie, -cratisme, -cratique : gouvernance)
-delphe : frère --> adelphe : ex.: Monadelphe : (1787) Mot dérivé de adelphe (« frère ») avec le préfixe mono- (« un »).
-drome : route --> piste
-èdre : édifice --> base -> face
-game : mariage --> -game : marié et -gamie : mariage
-leptie : faiblesse --> -lepsie : attaque (ex.: catalepsie, épilepsie et narcolepsie : attaque, emprise, action de saisir), "-leptie est une variante orthog. incorrecte de -lepsie, qui est dérivé sans doute du terme épileptique, ou bien du grec leptós « fin » avec un e bref, qui n'a rien à voir avec la famille de lẽpsis avec un ē long".
-saure : ancêtre --> qui ressemble à un lézard -> lézard
Doublons retirés :
-dynamique : dynamique ou mouvement
-phobe : a horreur ou qui a horreur
-trope : chercheur ou tendance --> orientation
-pathe : malade
Doubles sens ajoutés :
-mane : maniaque, mais aussi : main, ex.: quadrumane : quadru- et -mane
-mètre : mesure, mais aussi : matrice (ex.: endomètre)
Retirés :
-me : tumeur : trouvé nulle part
-n : particule : trouvé nulle part
-paroxysme : maximum : mot complet : aucun mot ne se termine par paroxysme
-philosophe : philosophe : déjà un mot composé : philo - sophia : celui qui aime la sagesse
Ajouts (complément) :
-centrisme : être centré autour --> centrage, ajout : -centre (ex.: épicentre), -centrique (centré, ex.: égocentrique : centré sur soi)
-cinèse : mouvement, et aussi -cinésie (-cinèse, -cinésie, -kinèse, -kinésie)
-gène : générateur, -genèse : commencement --> -gène : générateur / origine, -genèse : création ; ajout de -génie, -génisme, -génique : développement
-logue : spécialiste, ajout aussi de : discours (ex.: analogue : même discours, semblable)
-morphe : forme (ex.: amorphe : informe, anthropomorphe : qui ressemble à l'homme), ajout de -morphose : forme (métamorphose : changement de forme, anamorphose : modification de forme)
-technique : aussi -technie : technique (ex.: pyrotechnie)
Historique des versions
Version 1.08 du 13/05/2021
- Correction du bilan (retirer tous les mots trouvés de la liste des "Préfixes manquants fréquents").
Version 1.07 du 04/08/2020
- Nombre de mots existants : distinction entre le décompte avec les racines uniques, et le décompte total ;
- Liste d'exclusion : Lorsque le préfixe n'est pas en première position, on doit maintenant préciser sa position dans cette liste de définitions exclusives, exemple avec gram- : aérophotogrammétrique:3, kilogrammètre:2, photogrammètre:2, photogrammétrie:2, photogrammétrique:2
- Liste des verbes conjugués : fichier externe ;
- Définitions fausses : Affichage du nombre de définitions fausses dans le bilan ; lorsqu'il y a plusieurs sens pour un même segment, c'est plus simple de choisir un sens principal, et de préciser en exclusivité les mots pour les autres sens : on passe ainsi de 596 à 312 définitions fausses, ce qui est plus simple.
Version 1.06 du 28/06/2020
- Ajout du dictionnaire du Littré : 73192 mots, 24000 mots en plus : Liste24KAjoutsDuLittre.txt
6499 mots simples -> 7649 (1150 mots simples ajoutés)
9355 mots complexes -> 10799 (1444 mots complexes ajoutés)
Version 1.05 du 03/05/2020
- Beaucoup de mots ajoutés :
494 préfixes x 198 suffixes = 97 812 combinaisons ->
516 préfixes x 207 suffixes = 106 812 combinaisons.
6214 mots simples -> 6499 (285 mots simples ajoutés)
8906 mots complexes -> 9355 (449 mots complexes ajoutés)
- Gestion d'une liste de mots ajoutés au dictionnaire : logotron, podoclaste, agrophyphe (cropcircle), pifomètre, bullshitomètre, collapsologie, câlinothérapie, capitalocène, anarchosyndicaliste.
Version 1.04 du 05/05/2019
- Gestion des élisions (du o devant un autre o), par exemple paléontologie : ÉTUDE DE L'ANCIEN(NE) DE L'ÊTRE : palé(o) - onto - logie.
Version 1.03 du 20/01/2019
- Suppression de l'article le, la, l' dans le sens d'un segment : traitements spéciaux (/ -> ,) en premier et non en dernier ;
- Gestion des définitions fausses aussi pour les mots complexes avec plusieurs préfixes (quelques définitions ont été corrigées suite à une correction du code concernant les sens multiples de certains préfixes et suffixes) ;
- Modélisation des données sous forme json et relationnelle (base de données MS-Access.mdb) ;
- Normalisation des concepts (uniformisation du sens des concepts proches pour la modélisation des données) via la nouvelle feuille Excel SensConcept ;
- Unicité des racines et concepts : le champ unicité doit maintenant être obligatoirement renseigné pour préciser un sens distinct (sinon le segment qui doublonne sera signalé et ignoré) ;
- Détection des racines multiples : plus besoin, car on décompte le nombre de racines d'un concept, les racines multiples se retrouvent simplement via les concepts avec NbRacines > 1.
Version 1.02 du 14/09/2018
- Version Bridge React : Quiz : verrouillage du niveau pendant le quiz.
Version originale 1.01 du 02/09/2018
Liens
- Wiktionnaire : Annexe:Préfixes en français
https://fr.wiktionary.org/wiki/Annexe:Préfixes en français
- Wiktionnaire : Annexe:Suffixes en français
https://fr.wiktionary.org/wiki/Annexe:Suffixes en français
- Wiktionary:
Appendix:English prefixes
https://en.wiktionary.org/wiki/Appendix:English_prefixes
- Wiktionary:
Appendix:English suffixes
https://en.wiktionary.org/wiki/Appendix:English
suffixe
- Lexique des affixes (préfixes et suffixes) du Dr Aly Abbara
www.aly-abbara.com/litterature/medicale/affixes/a.html
- Le dictionnaire des suffixes du Robert illustré
http://robert-illustre.lerobert.com/pdf/dictionnaire-des-suffixes.pdf (lien perdu)
- Liste des mots fléchis (verbes conjugués, pluriels, ...) du dictionnaire français DELA
http://infolingu.univ-mlv.fr/DonneesLinguistiques/Dictionnaires/telechargement.html
- Liste des mots fléchis du dictionnaire frgut
http://www.pallier.org/extra/liste.de.mots.francais.frgut.txt
Voir aussi
- La machine à inventer des mots à partir des Chaînes de Markov et les n-grams de la langue.
- VBTextFinder :
un moteur de recherche de mot dans son contexte en VBA, VB6 et VB .Net
Code source : VBTextFinder.vbproj.html
Exemple de recherche des termes
"radio" et "graphie" dans le dictionnaire DELA
via l'outil VBTF : RadioGraphie.
- XL2Csv :
Convertir un fichier Excel en fichiers Csv (ou en 1 fichier txt)
Code source : XL2Csv.vbproj.html
Cet utilitaire peut convertir le
classeur Logotron en csv en un clic depuis l'explorateur de fichier.
- File2XL : Open a csv file into MS-Excel with pre-formatted cells
File2XL source code in VB .Net : File2XL.vbproj.html
Cet utilitaire peut ouvrir
facilement un fichier csv sous Excel, sans problème de conversion (par exemple
le tiret devant le suffixe est confondu avec le signe - des formules, si on
ouvre directement avec Excel un fichier csv du Logotron).
- DBComp2 : le comparateur de structure de base de données Access (ou ODBC) avec Windiff
Code source : DBComp.vbp.html